
Compute Instances¶
Slurm partitions¶
The new hpc service Nimbus provides user access to an array of different compute instances. These instances are accessed through different slurm partitions.
In order to list the partitions issue the following command:
sinfo
which will list the partitions, the nodes in the partitions, availability and the current state:
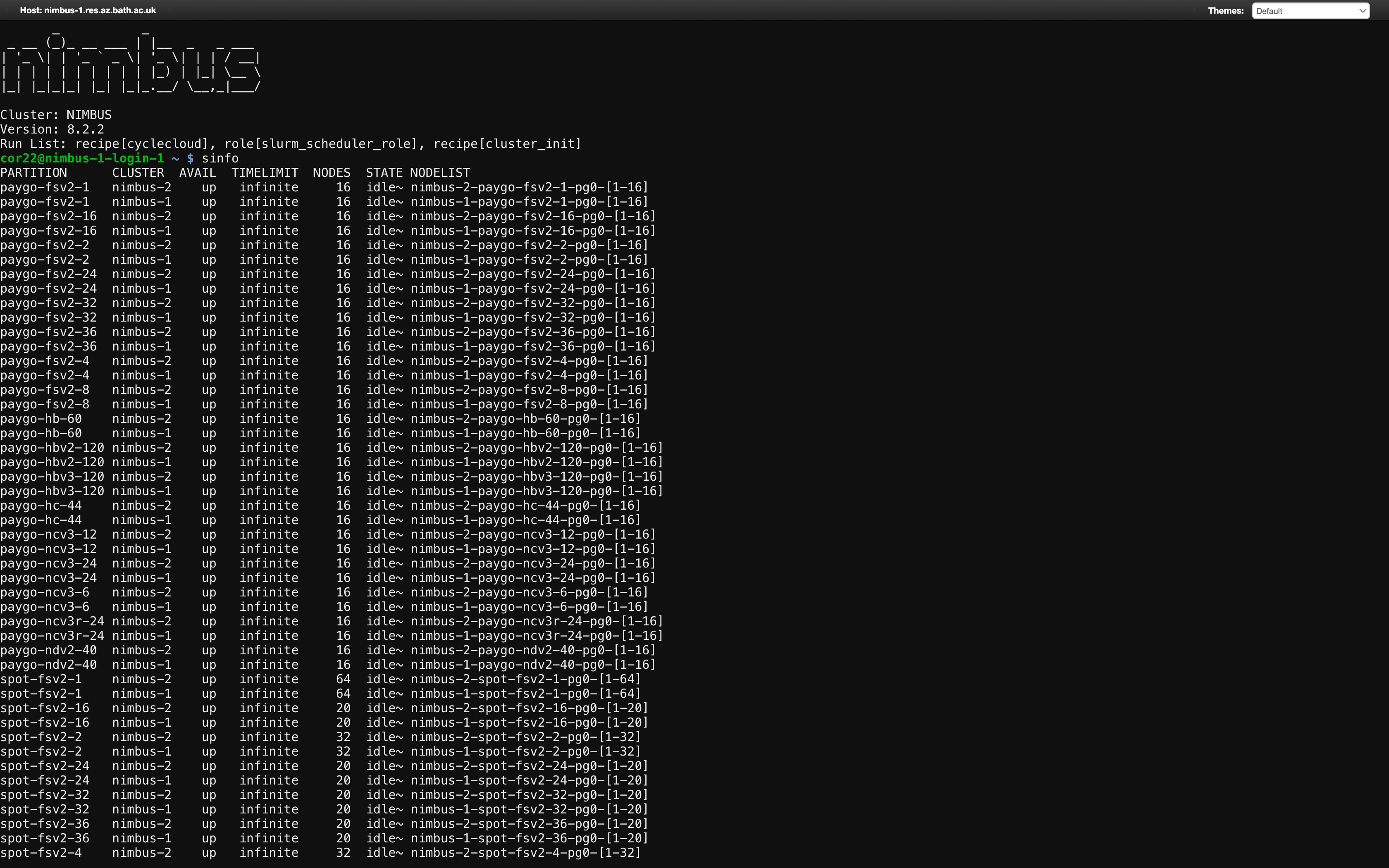
The partitions follow a naming converntion
[pricing tier]-[instance type]-[no of cpus-per-node]
So, for example the partition spot-hbv3-120 is for spot priced hbv3 instances with 120 CPUs per node, while paygo-hc-44 is for pay-as-you-go priced hc instances with 44 CPUs per node.
Compute Instances¶
The instance types currently available are listed below:
| Instance type | CPU model | vCPUS | GPU model | vGPUS |
|---|---|---|---|---|
| fsv2 | Intel Skylake | 2,4,8,16,32,48,64,72 | - | - |
| hb | AMD Epyc Naples | 60 | - | - |
| hbv2 | AMD Epyc Rome | 120 | - | - |
| hbv3 | AMD Epyc Milan | 120 | - | - |
| hc | Intel Skylake | 44 | - | - |
| ncv3 | Intel Broadwell | 6 | Tesla V100 | 1 |
| ncv3 | Intel Broadwell | 12 | Tesla V100 | 2 |
| ncv3 | Intel Broadwell | 24 | Tesla V100 | 4 |
| ncv3r | Intel Broadwell | 24 | Tesla V100 | 4 |
| ndv2 | Intel Skylake | 40 | Tesla V100 | 8 |
As mentioned above these instances are referenced in the slurm partition, along with the number of CPUs and the pricing tier.
Choosing the right instance¶
Choosing the correct compute instance and partition will depend primarily on the code/caculation you are running, but it also will depend on cost, runtime and whether an interruption is acceptable (more on that in spot vs pay-as-you-go).
The compute instances listed above can be seperated into different types as described by azure:
- High performance compute: hb, hbv2, hbv3 & hc series
- GPU enabled: ncv3, ncv3r, & ndv2
- Compute Optimised: fsv2
The descriptions of the instances provided by Azure are as follows:
- High Performance Compute:
Our fastest and most powerful CPU virtual machines with optional high-throughput network interfaces (RDMA). - GPU enabled:
Specialized virtual machines targeted for heavy graphic rendering and video editing, as well as model training and inferencing (ND) with deep learning. Available with single or multiple GPUs. - Compute Optimised:
High CPU-to-memory ratio. Good for medium traffic web servers, network appliances, batch processes, and application servers.
Briefly:
- The
hb*instances are suggested for applications driven by memory bandwidth such as OpenFOAM and ANSYS. - The
hc*&f*instances are suggested for applications driven by compute such as HPL and ORCA. - The
n*partitions are for GPU accelerated workloads and visualization sessions.
If in doubt - ask or test!
Spot vs Pay-As-You-Go¶
We have mentioned the pricing tier above, which is referenced in the slurm partition names. This pricing tier refers to the two different tiers:
- Spot
- Pay-As-You-go
Spot pricing allows access to unused Azure compute capacity at large discounts, up to 90%, compared to Pay-As-You-Go prices. The drawback is that the job can be interrupted at any time and be evicted, depending on the available Azure capacity.
Deciding whether to use the Spot or Pay-As-You-Go tiers will depend on how easy it is to pick up your calculation should it be evicted, the time scales for you calculation and your available budget.
If your job is subject to an eviction you will recieve a message in the stdout of the job, and the status in the finance portal will be EVICTED. At present if a job is evicted you will not be charged for it, though this may change in future.
Restrictions on Instances¶
The only restriction put in place by Research Computing on the size of jobs you are able to run on Nimbus is to restrict the number of nodes you can run on using the fsv2 instances to one. These are RDMA connected, and you cannot run single jobs across multiple nodes, hence the restriction.
All other restrictions are put in place by your Resource Allocation Administrators using the finance portal. Should you wish to change the restrictions either do so in the portal, or contact the person that has given you access to the resource allocation and request they do so.
Indicative Cost of Instances¶
It is important to emphasise that different compute instances will incur different costs.
A cost calculator has been launched that lists the current prices for each compute instance, as well as allowing you to cost up resources for inclusion in funding proposals.