University of Bath
Research Computing Team (DDaT)
Nimbus HPC Documentation
Introducing High Performance Computing¶
What is HPC and why is it different to using your desktop?¶
“High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much higher performance than one could get out of a typical desktop computer or workstation in order to solve large problems in science, engineering, or business.” - insideHPC

Lets consider seeveral research scenarios:
- A statistics student wants to cross-validate a model. This involves running the model 1000 times – but each run takes an hour. Running the model on a laptop will take over a month! In this research problem, final results are calculated after all 1000 models have run, but typically only one model is run at a time (in serial) on the laptop. Since each of the 1000 runs is independent of all others, and given enough computers, it’s theoretically possible to run them all at once (in parallel).
- A genomics researcher has been using small datasets of sequence data, but soon will be receiving a new type of sequencing data that is 10 times as large. It’s already challenging to open the datasets on a computer – analyzing these larger datasets will probably crash it. In this research problem, the calculations required might be impossible to parallelize, but a computer with more memory would be required to analyze the much larger future data set.
- An engineer is using a fluid dynamics package that has an option to run in parallel. So far, this option was not used on a desktop. In going from 2D to 3D simulations, the simulation time has more than tripled. It might be useful to take advantage of that option or feature. In this research problem, the calculations in each region of the simulation are largely independent of calculations in other regions of the simulation. It’s possible to run each region’s calculations simultaneously (in parallel), communicate selected results to adjacent regions as needed, and repeat the calculations to converge on a final set of results. In moving from a 2D to a 3D model, both the amount of data and the amount of calculations increases greatly, and it’s theoretically possible to distribute the calculations across multiple computers communicating over a shared network.
In all these cases, access to more (and larger) computers is needed. Those computers should be usable at the same time, solving many researchers’ problems in parallel.
PC vs HPC¶
Your PC is your local computing resource, good for small computational tasks. It is flexible, easy to set-up and configure for new tasks, though it has limited computational resources.

Let’s dissect what resources programs running on a laptop require:
- the keyboard and/or touchpad is used to tell the computer what to do (Input)
- the internal computing resources Central Processing Unit (CPU_ and Memory are used to perform calculations the Screen Display depicts progress and results (Output) alternatvely, both input and output can be done using data stored on Disk or on a Network
- Schematically, this can be reduced to the following:

If Our PC isnt Powerful Enough?¶
When the task to solve become heavy on computations, the operations are typically out-sourced from the local laptop or desktop to elsewhere. Take for example the task to find the directions for your next business trip. The capabilities of your laptop are typically not enough to calculate that route in real time, so you use a website, which in turn runs on a computer that is almost always a machine that is not in the same room as you are. Such a remote machine is generically called a server.

The internet made it possible for these data centers to be far remote from your laptop.
The server itself has no direct display or input methods attached to it. But most importantly, it has much more storage, memory and compute capacity than your laptop will ever have. However, you still need a local device (laptop, workstation, mobile phone or tablet) to interact with this remote machine.
HPC Cluster¶
If the computational task or analysis to complete is daunting for a single server, larger agglomerations of servers are used. These go by the name of clusters or supercomputers.
A HPC system is typically described as a cluster as it is made up of a cluster of computers, or compute nodes. Each individual compute node is typically a lot more powerful than any PC - i.e. more memory, many more and faster CPU cores.
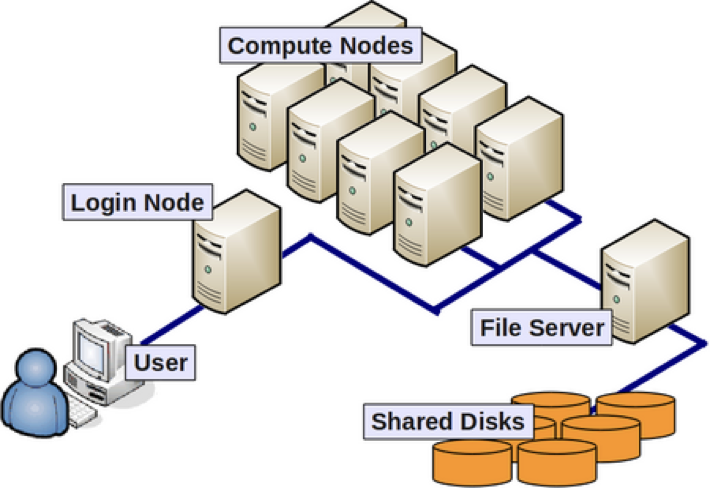
The methodology of providing the input data, communicating options and flags as well as retrieving the results is quite different to using a plain laptop. Moreover, using a GUI style interface is often discarded in favor of using the command line. This imposes a double paradigm shift for prospect users:
- they work with the command line (not a GUI style user interface)
- they work with a distributed set of computers (called nodes)
Parallelisation¶
But how do we use the resources on the cluster?
Lets start with the idea of processing 1 input file to generate 1 output (result) file. On a personal computer this would happen with a single core in the CPU.

On a cluster we have access to many cores on a single or multiple nodes, the way a HPC can make a simulation faster is to distribute the simulation to different cores so that the CPUS working concurrently can speed up execution. For this work the software you want to run needs to be able to use the differents cores (or threads). This implies that it needs to be written and compiled with the appropriate parallel library MPI (message passing interface) for multicores and OpenMP for multi threading.
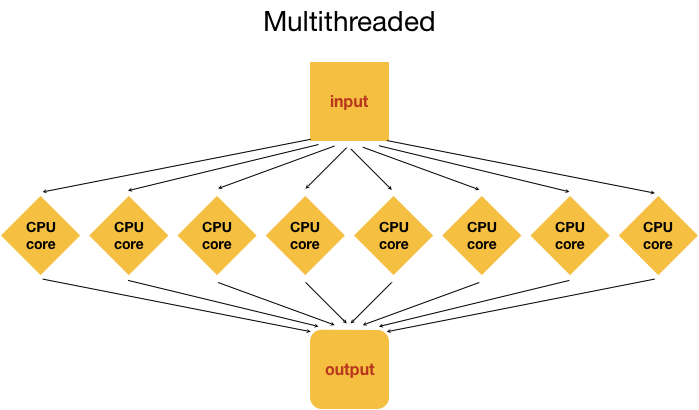
As we have already seen, the power of HPC systems comes from parallelism, i.e. having lots of processors/disks etc. connected together rather than having more powerful components than your laptop or workstation.
When running programs on HPC that use the MPI (Message Passing Interface) parallel libraryin general, they need to be launched in job submission scripts in a different way to serial programs and users of parallel programs on HPC systems need to know how to do this. Specifically, launching parallel MPI programs typically requires four things: